Feature Overview
BibiGPT has recently integrated ByteDance’s Doubao Seed-1.6 series of large language models, aimed at satisfying users’ desire to try the latest AI technologies and enhancing product competitiveness. Users can now directly select the Thinking, Standard, and Flash models of Doubao Seed-1.6 via the “Summary Settings” dropdown menu on the BibiGPT home page to achieve one-click audio and video summarization. Developed by the ByteDance Seed team, the Seed-1.6 model fuses multimodal capabilities, supporting adaptive deep thinking, multimodal understanding, and graphical operations, with support for 256K long-context inference. It performs excellently in multiple benchmarks and visual tasks, especially through Adaptive CoT technology, which automatically triggers the thinking process based on problem difficulty to achieve a balance between model performance and inference. Here is an example of the function interface: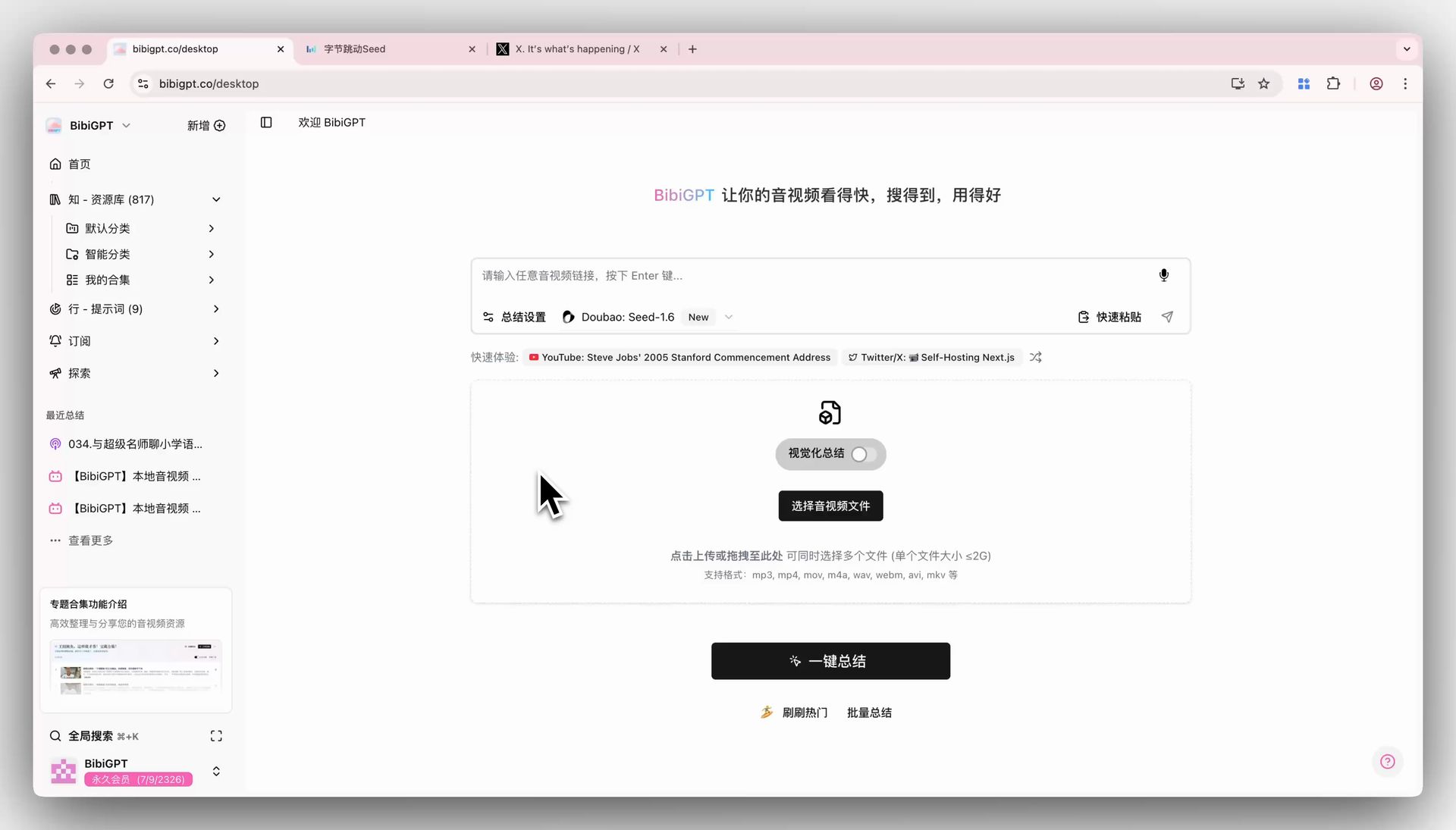
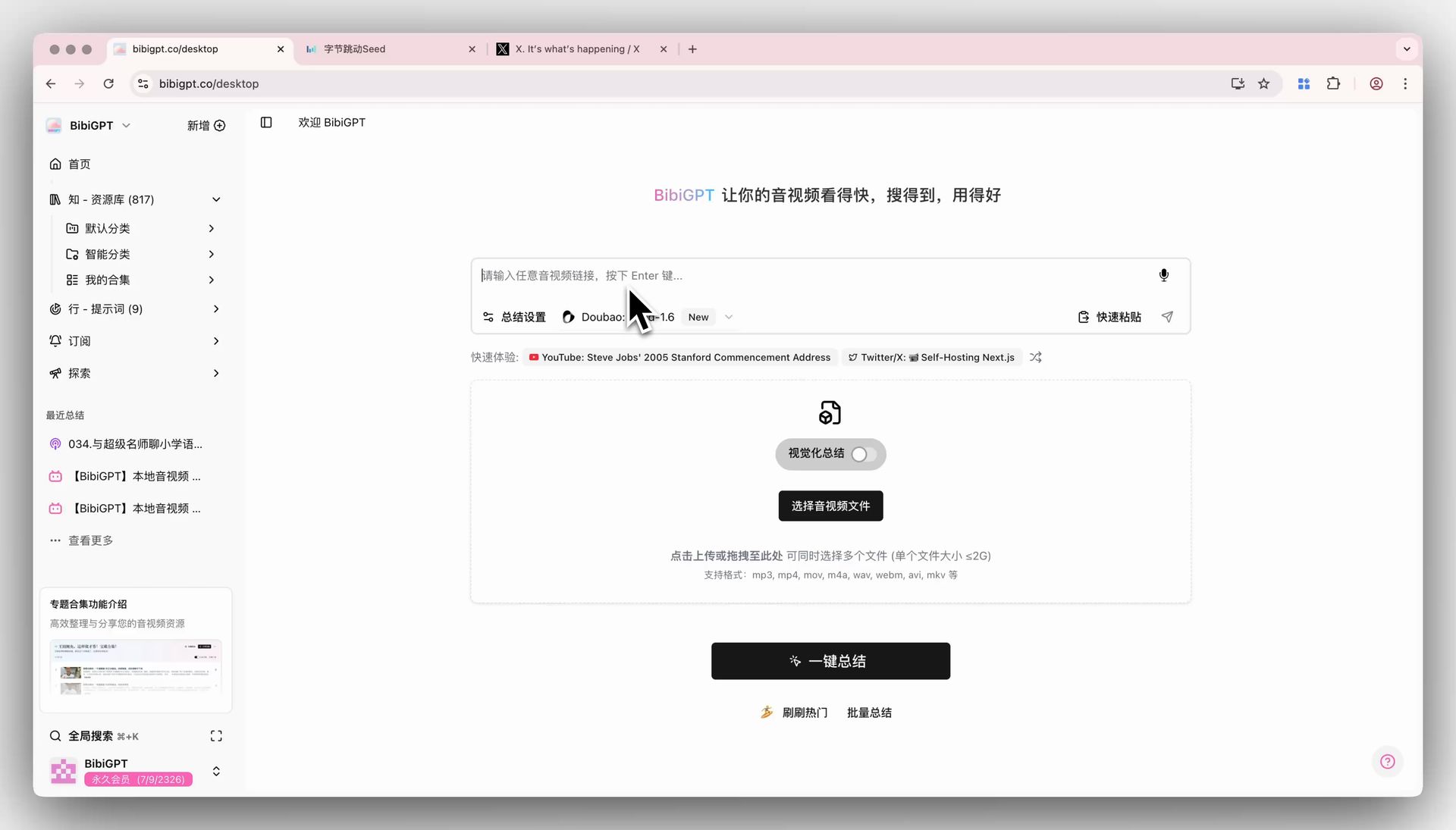
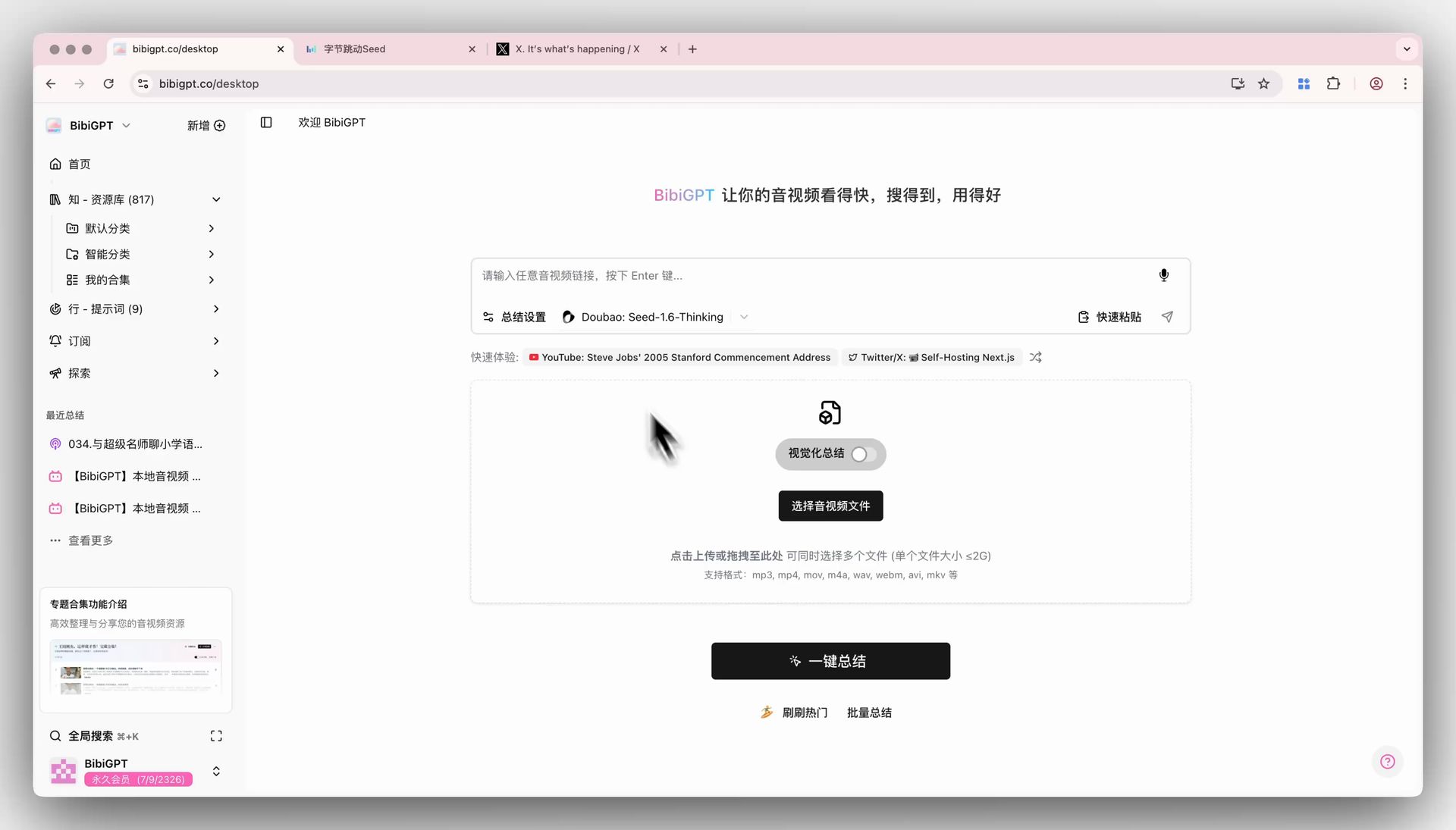
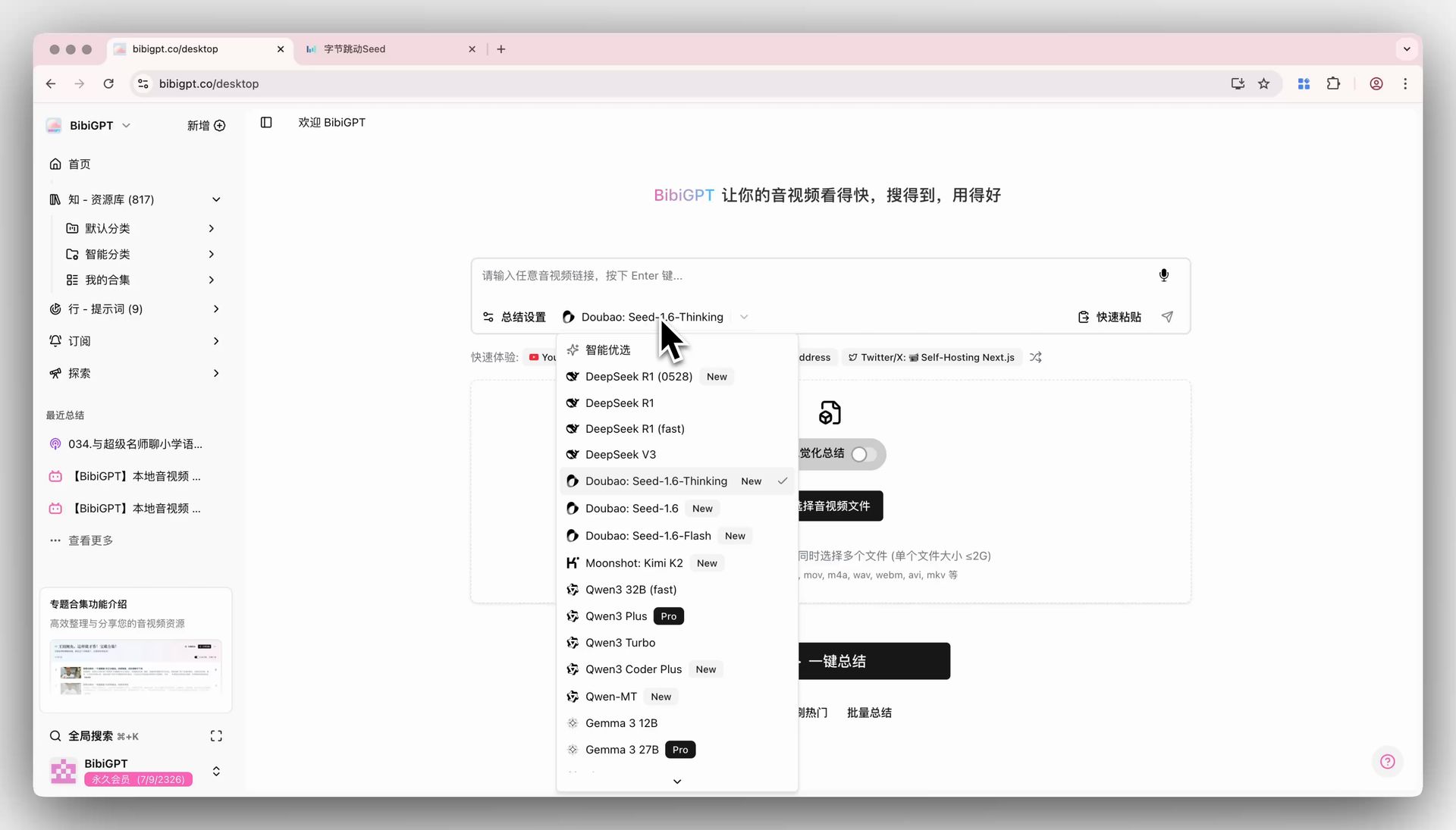
Solved Pain Points
I want to be able to try the newest and most powerful large language models on the market to summarize audio and video content, thereby obtaining higher quality and more accurate summary results.Core Features
- BibiGPT recently integrated ByteDance’s Doubao Seed-1.6 series of large language models.
- Users can directly choose from Thinking, Standard, and Flash models of Doubao Seed-1.6 via the “Summary Settings” menu.
- Seed-1.6 features multimodal capabilities, 256K long-context support, and Adaptive CoT technology for balanced performance.
- BibiGPT continuously connects to the latest LLMs, allowing users to experience cutting-edge AI summarization firsthand and improve content quality through simple selection.
Feature Highlights
BibiGPT continuously connects to the latest large language models on the market (such as ByteDance’s Doubao Seed-1.6 series), allowing users to experience cutting-edge AI summarization capabilities firsthand. Quality and efficiency of audio and video summaries can be improved through a simple selection.Applicable Scenarios
- I want to be able to try the newest and most powerful large language models on the market to summarize audio and video content, thereby obtaining higher quality and more accurate summary results.